
Solution MongoDB : NoSQL
Langage : javascript Type: Document
Description du modèle de document utilisé dans les différents projets
DeepBDD : est une plateforme Dictionnaire dédiée à l’anglais contemporain. Elle regroupe les dictionnaires Anglais, Américain et Australien pour offrir aux chercheurs des fonctionnalités de manipulation et d’extraction ainsi que des fonctionnalités d’enrichissement de ce gisement de données.
Modèle XML
<Entry>
<Head>
<HWD>Aarhus</HWD>
</Head>
<PronCodes>
<PRON>ˈɔː huːs</PRON>
<VARPRON>ˈɑː-, -hʊs</VARPRON>
<AMEPRON>ˈɔːr-</AMEPRON>
<AMEVARPRON>ˈɑːr-</AMEVARPRON>
</PronCodes>
<DESC>—Danish</DESC>
<WORD>Århus </WORD>
<ForeignPron>
<PronCodes>
<PRON>ˈɔː huːʔs</PRON>
</PronCodes>
</ForeignPron>
</Entry>Modèle JSON – MongoDB
{
"_id" : ObjectId("6626177d4c56c07afaa398ff"),
"Head" : {
"HWD" : "Aarhus",
"head_s" : "Aarhus"
},
"PronCodes_0" : {
"PRON" : "ˈɔː huːs",
"VARPRON" : "ˈɑː-, -hʊs",
"AMEPRON" : "ˈɔːr-",
"AMEVARPRON" : "ˈɑːr-"
},
"DESC_0" : "—Danish",
"WORD0" : "Århus ",
"ForeignPron" : {
"PronCodes" : {
"PRON" : "ˈɔː huːʔs"
},
"DESC" : "",
"WORD" : "Århus "
},
"ide_deepbdd" : "6a91f25c007d11efbfe2c96a2935a937"
}
Dans ce projet, les éléments provenant des fichiers XML sont structurés de manières différentes. De plus des adaptations ont été prises pour conserver des informations associées à l’édition. Ces éléments rajoutés de type <lpdfont>, <TEXT> ….n’ont aucune utilité pour notre plateforme, et seront ainsi éliminés par un pré-traitement du fichier. Ce module de prétraitement s’appuie en partie sur des bibliothèques de manipulations de XML qui ont présenté des défauts d’interprétation des fichiers d’origine dû à la structure même des fichiers et à l’usage de balise ne respectant pas les conventions XML.
<Entry>
<Head>
<HWD>Aberdeen</HWD>
</Head>
<DESC>place in Scotland</DESC>
<PronCodes>
<PRON>ˌæb ə ˈdiːn</PRON>
<AMEPRON>
<TEXT>-</TEXT>
<sup>ə</sup>
<TEXT>r-</TEXT>
</AMEPRON>
</PronCodes>
<DESC>—but places in the US are</DESC>
<PronCodes>
<PRON>ˈ•••</PRON>
</PronCodes>
<Derivative>
<DERIV>~shire</DERIV>
<PronCodes>
<PRON>ʃə</PRON>
<VARPRON>
<TEXT>-ʃɪə, §-ʃa</TEXT>
<i>ɪ</i>
<TEXT>‿ə</TEXT>
</VARPRON>
<AMEPRON>ʃɪr</AMEPRON>
<AMEVARPRON>
<TEXT>-ʃ</TEXT>
<sup>ə</sup>
<TEXT>r</TEXT>
</AMEVARPRON>
</PronCodes>
</Derivative>
</Entry>{
"_id" : ObjectId("6626177d4c56c07afaa39904"),
"Head" : {
"HWD" : "Aberdeen",
"head_s" : "Aberdeen"
},
"DESC_0" : "place in Scotland",
"PronCodes_0" : {
"PRON" : "ˌæb ə ˈdiːn",
"AMEPRON" : "-[sup]ə[/sup]r-"
},
"DESC_1" : "—but places in the US are",
"PronCodes_1" : {
"PRON" : "ˈ•••",
"AMEPRON" : "ˈ•••"
},
"Derivative" : [
{
"DERIV" : "~shire",
"PronCodes" : {
"PRON" : "ʃə",
"VARPRON" : "-ʃɪə, §-ʃa[i]ɪ[/i]‿ə",
"AMEPRON" : "ʃɪr",
"AMEVARPRON" : "-ʃ[sup]ə[/sup]r"
}
}
],
"ide_deepbdd" : "6a938d9c007d11efbfe2c96a2935a937"
}
Utilisations avancées Bucket et facet :
Buckets : l’instruction bucket permet de faire des agrégations rapides sur une collection pour connaitre rapidement la distribution selon une grandeur.La distribution peut être fixée ou définie de façon automatique avec bucketAuto.
Deux illustrations de cette méthode sur les documents de la plateforme Emolgine.
db.getCollection('D_G-5HT7').aggregate({$bucket:{groupBy:"$minimizedAffinity",boundaries:[-14,-9,-8,-6],default:"other",output:{nb:{$sum:1}}}}){ “_id” : -14, “nb” : 56321 }
{ “_id” : -9, “nb” : 45969 }
{ “_id” : -8, “nb” : 87741 }
{ “_id” : “other”, “nb” : 23 }
Instruction équivalente pour vérifier l’intervalle et les valeurs :
db.getCollection('D_G-5HT7').find({$and:[{"minimizedAffinity":{$gt:-14}},{"minimizedAffinity":{$lt:-9}}]}).count() ==> 56321
db.getCollection('D_G-5HT7').aggregate({$bucketAuto:groupBy:"$sascore",buckets:5,granularity:"R20",output:{nb:{$sum:1}}}}){ “_id” : { “min” : 0.9, “max” : 3.15 }, “nb” : 45375 }
{ “_id” : { “min” : 3.15, “max” : 4 }, “nb” : 59856 }
{ “_id” : { “min” : 4, “max” : 4.5 }, “nb” : 40294 }
{ “_id” : { “min” : 4.5, “max” : 5.6000000000000005 }, “nb” : 41634 }
{ “_id” : { “min” : 5.6000000000000005, “max” : 8 }, “nb” : 2895 }
Facets:
db.getCollection('D_G-5HT7').aggregate([{$facet:{"efficiency":[{$bucketAuto:{groupBy:"$minimizedAffinity",buckets:4,output:{"eff":{$sum:1}}}}],"affinity":[{$bucketAuto:{groupBy:"$efficiency",buckets:4}}]}}]){ “efficiency” : [ { “_id” : { “min” : -14.78564, “max” : -9.21796 }, “eff” : 47514 }, { “_id” : { “min” : -9.21796, “max” : -8.14746 }, “eff” : 47515 }, { “_id” : { “min” : -8.14746, “max” : -7.17637 }, “eff” : 47514 }, { “_id” : { “min” : -7.17637, “max” : -6.00007 }, “eff” : 47511 } ], “affinity” : [ { “_id” : { “min” : -0.69, “max” : -0.43 }, “count” : 51772 }, { “_id” : { “min” : -0.43, “max” : -0.39 }, “count” : 47604 }, { “_id” : { “min” : -0.39, “max” : -0.35 }, “count” : 48887 }, { “_id” : { “min” : -0.35, “max” : -0.25 }, “count” : 41791 } ] }
Description des requêtes d’extraction dans les différents projets
Illustrations de requêtes selon différents schémas de données (document) avec l’interprétation de fields de type tableau (links) dans la structure de document des molécules :
Recherche des molécules ayant 6 liens vers la chimiothèque.
db.getCollection('D_G-5HT7').aggregate([{$match:{"links.Chimiotheque":{$ne:null}}},{$project:{_id:"$inchikey","size":{$size:"$links.Chimiotheque"}}},{$match:{"size":{$eq:6}}}])Intégration de ces requêtes dans Spring Boot :
Les requêtes intégrées dans un web service sous Spring Boot.
Constitution d’une requête pour extraire les éléments selon des critères composés par l’utilisateur. Dans le module d’exploitation des molécules, l’interface autorise l’utilisateur à préciser les intervalles de sélection des molécules selon les différentes grandeurs possibles:
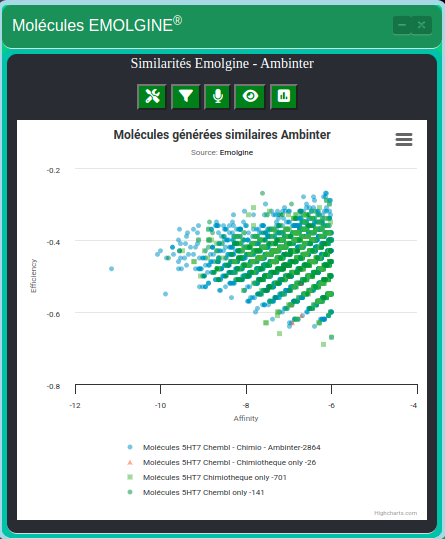
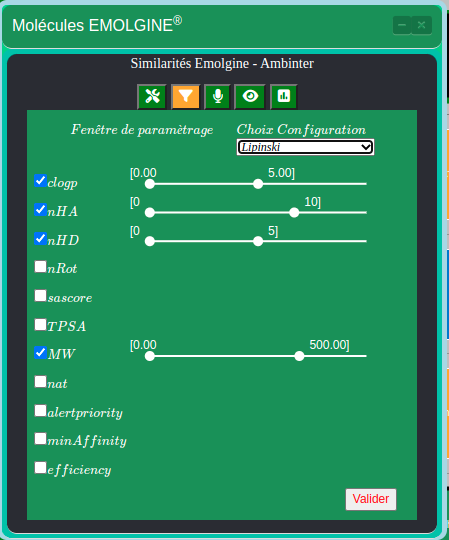
Comment implémenter ces filtres du côté web service ?
On passe en mode json l’ensemble de la sélection effectuée par l’utilisateur .
{“parametres”:”{“clogP”:{“min”:”0.00″,”max”:”5.00″},”nHA”:{“min”:”0″,”max”:”10″},”nHD”:{“min”:”0″,”max”:”5″},”MW”:{“min”:”0.00″,”max”:”500.00″}}”}
@RequestMapping(value = "/find_inter_ambinter", method = POST)
public Map<String,List<MoleculeAmbinter>> find_inter_ambinter(@RequestBody Map<String, Map<String,Map<String, String>>>body) {
final Map<String, Map<String, String>> collection = body.get("parametres");
String Coll = "D_S_Ambinter_5HT7";
List<AggregationOperation> liste_op=new ArrayList<AggregationOperation>();
collection.keySet().forEach(elem -> {
float fmin = Float.parseFloat(collection.get(elem).get("min"));
float fmax = Float.parseFloat(collection.get(elem).get("max"));
liste_op.add(Aggregation.match(new Criteria(elem).gt(fmin).lt(fmax)));
});
Map<String, List<MoleculeAmbinter>> liste_trouves = find_ambinter_5HT7(liste_op);
return liste_trouves;
}On compose l’ensemble de la requête dans la fonction suivante et on exécute l’appel à MongoDB
public Map<String, List<MoleculeAmbinter>> find_ambinter_5HT7(List<AggregationOperation> liste_op) {
Map<String, List<MoleculeAmbinter>> liste_trouves = new HashMap<>();
// uniquement en lien avec la Chembl
List<AggregationOperation> liste_op_temp=new ArrayList<AggregationOperation>();
liste_op.forEach(op-> {
liste_op_temp.add(op);
});
AggregationOperation matchPost1 = Aggregation.match(new Criteria("links.Chembl").exists(true));
AggregationOperation matchPost2 = Aggregation.match(new Criteria("links.Chimiotheque").exists(false));
AggregationOperation projectStage = Aggregation.project(MoleculeAmbinter.class)
.and(ArrayOperators.Size.lengthOfArray("links.Chembl")).as("sizeChembl")
.andExclude("_id");
AggregationOperation matchPre1 = Aggregation.match(new Criteria("sizeChembl").gt(0));
AggregationOperation matchPre2 = null;
liste_op_temp.add(matchPost1);
liste_op_temp.add(matchPost2);
liste_op_temp.add( projectStage);
liste_op_temp.add(matchPre1);
Aggregation aggregation = Aggregation.newAggregation(liste_op_temp);
AggregationResults<MoleculeAmbinter> output = mongoTemplate.aggregate(aggregation, "D_S_Ambinter_5HT7",
MoleculeAmbinter.class);
List<MoleculeAmbinter> result = output.getMappedResults();
liste_trouves.put("spgoo_chembl", result);
return liste_trouves;
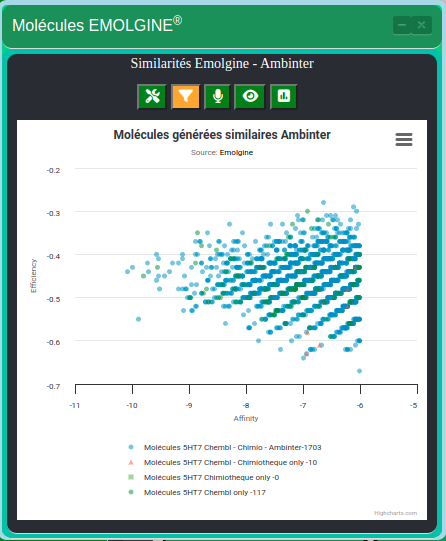
}Pour obtenir le résultat suivant :
DeepBDD – Décembre 2025 :
Transfert et intégration des différentes collections corrigées et complétées par JMF dans le cadre de deepBdd-Bddictionnairique
Les instructions sous MongoDB pour effectuer ce type de copie sont les suivantes:
db.collection1.find().forEach(function(x) {db.cons2025Finale.insert(x);})Ce procédé permet de copier avec l’id les éléments d’une collection à une autre de façon intégrale, ce qui évite de dupliquer certains éléments dans le cas où des requêtes auraient des intersections non nulles.
Pour le détail de cette opération voir la CDA-DeepBdd
Passy – DPFV Décembre 2025 :
Dans le cadre de Passy, il a fallu développer du côté du web service une fonction d’extraction des segments situés avant et après un segment spécifique. Pour ce faire, nous avons rajouté l’ensemble des segments des enregistrements de type TRAITEMENT d’ESLO. Développer une fonction d’extraction qui s’appuie sur les attributs DEBUT et FIN de la collection. La fonction équivalente sous MongoDB est :
db.getCollection(‘eslo2’).aggregate([{“$addFields”:{nouv:{$toDouble:”$debut”}}},{$match:{$and:[{$expr:{$gt:[“$nouv”,280.261]}},{$expr:{$lt:[“$nouv”,301.261]}},{“enreg”:”ESLO2_ENT_1010_C”}]}}])
Ce qui nous donne le code suivant dans Spring Boot :
// chercher les segments avant et après celui courant
// on va prendre le debut -10 et la fin + 10
// db.getCollection('eslo2').aggregate([{"$addFields":{yvan:{$toDouble:"$debut"}}},{$match:{$and:[{$expr:{$gt:["$yvan",280.261]}},{$expr:{$lt:["$yvan",301.261]}},{"enreg":"ESLO2_ENT_1010_C"}]}}])
@RequestMapping(value = "/get_avant_", method = POST)
@PostMapping("json")
public List<Proposition_IA> get_avant_(@RequestBody Map<String, String> body) {
String locuteur = body.get("locuteur");
double debut= Double.parseDouble(body.get("debut"));
double fin= Double.parseDouble(body.get("fin"));
String enreg= body.get("enreg");
System.out.println("get_avant_: "+locuteur +" " + debut + " " +fin +" " + enreg );
AddFieldsOperation Addfield = Aggregation.addFields().addField("yvan").withValue(ConvertOperators.ToDouble.toDouble("$debut")).build();
// avant
Criteria critres = new Criteria().andOperator(
Criteria.where("yvan").lt(debut),
Criteria.where("yvan").gt(debut-10),
Criteria.where("enreg").regex(enreg));
MatchOperation matchStage = Aggregation.match(critres);
Aggregation aggregation = Aggregation.newAggregation(Addfield, matchStage);
AggregationResults<Proposition_IA> output_avant = mongoTemplate.aggregate(aggregation, "eslo2", Proposition_IA.class);
List<Proposition_IA> avant_result = output_avant.getMappedResults();
System.out.println(avant_result);
return avant_result;
}