
CDA FRAPéOR : resp Badreddine Hamma
Ressources : Yvan Stroppa (Déc 2024 – )

Projet de constitution d’un corpus d’allophones d’Orléans.
Une plateforme de saisie de corpus a été développée pour permettre l’alimentation des enregistrements sonores produits par les contributeurs à ce projet.
L’objectif de ce projet est la constitution d’un corpus sonores d’allophone d’Orléans qui devra permettre de compléter le corpus d’ESLO. L’ensemble des éléments ainsi constitué devrait permettre d’obtenir une représentation plus exacte de notre environnement.
Pour permettre cette réalisation, nous avons développé une plateforme web qui offre un contexte d’alimentation assisté des enregistrements sonores. Elle est disponible à l’adresse suivante : https://frapeor.org
Cette plateforme a été organisée pour suivre le processus défini avec B. Hamma dans l’alimentation du corpus, à savoir :
Utilisation d’une solution de transcription automatique des enregistrements.
La procédure de transcription passe par un pipeline basé sur Kafka et d’un transcripteur de type WhisperUI.
Kakfa : détail de la mise en place
WhisperUI : est utilisé à partir d’une image Docker de type Whisper-faster que l’on a installé sur une station de SPGoO. A partir de cette image on peut effectuer les transcriptions en automatique à partir du modèle medium de l’outil et mettre ainsi la transcription à disposition de l’utilisateur pour correction.
Description de l’installation de Whisper sur la station :
Fichier de lancement
docker run -d \
--name=faster-whisper \
-e PUID=1000 \
-e PGID=1000 \
-e TZ=Etc/UTC \
-e WHISPER_MODEL=medium \
-e WHISPER_BEAM=1 \
-e WHISPER_LANG=fr \
-p 10300:10300 \
-v /home/ystroppa/frapeor/whisper/data:/config \
--restart unless-stopped \
lscr.io/linuxserver/faster-whisper:latestUtilisation de Whisper en mode manuelle :
>>> from faster_whisper import WhisperModel
>>> model_size="medium"
>>> model = WhisperModel(model_size, device="cpu", compute_type="int8")
>>> segments, info = model.transcribe("Enregistrement_.mp3", beam_size=5)
>>> for segment in segments:
... print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))Interface de saisie et de correction
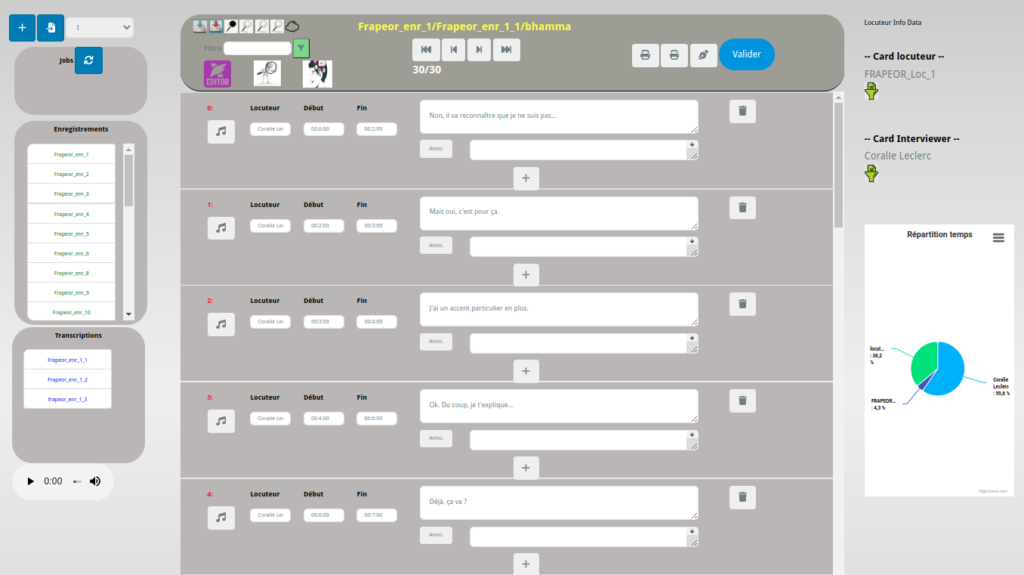
Une interface web a été entièrement développée pour permettre de travailler sur les transcriptions produites par Whisper. Elle permet à l’utilisateur de consulter les différentes séquences, de les écouter et de les corriger car le transcripteur commet des erreurs qu’il est nécessaire de corriger. Attention cette correction ne prendre en compte que le forme attendue et non pas la forme entendue. L’indication des erreurs commises se passera à l’étape suivante.
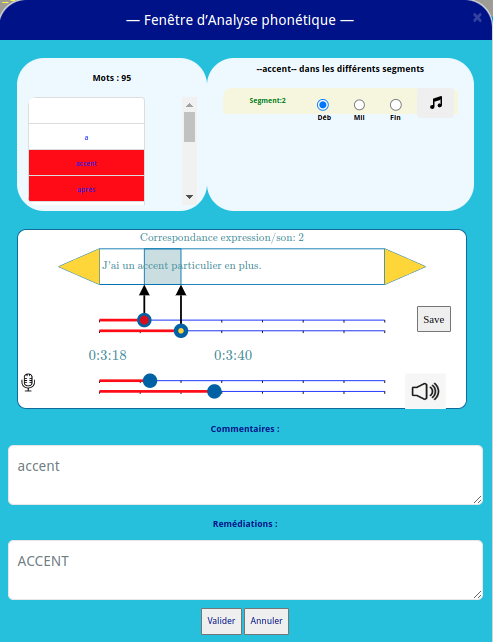
Marqueur des erreurs :
Dans cette partie, il est nécessaire de repérer les mots/expressions mal prononcés. Pour cela, une fenêtre dédiée va permettre à l’utilisateur d’apposer des marqueurs sur le ou les mots mal prononcés. A chaque expression repérées, il pourra également ajouter des commentaires sur le contexte du défaut et ses possibilités de corrections.
Interface de contrôle des éléments saisis
Les éléments de diagnostics fournis sont contrôlés par la suite par la responsable de la formation B. Hamma pour garantir la qualité des éléments fournis. Pour ce faire, une gestion des droits a été mise en place pour permettre et rendre accessible la production d’un utilisateur à un autre utilisateur avec des privilèges.