
PASSY-DPFV — resp. Gabriel Bergounioux
Appui SPGoO : Yvan Stroppa

Construction d’une plateforme nommée Passy sur la base de la réalisation effectuée pour MP Tours (DeepBdd-Bddictionnairique) dans un contexte de langue française. Ce travail est réalisé en collaboration avec G. Bergounioux et avec la participation de l’ATILF (Nancy).
Objectif : concevoir une plateforme Web d’alimentation, de collecte et d’exploitation de données phonétiques.
Importation des données du TLF
Première étape: récupération des données du TLF de l’ATILF pour constituer la base de départ de notre corpus phonétique soit 54734 entrées.
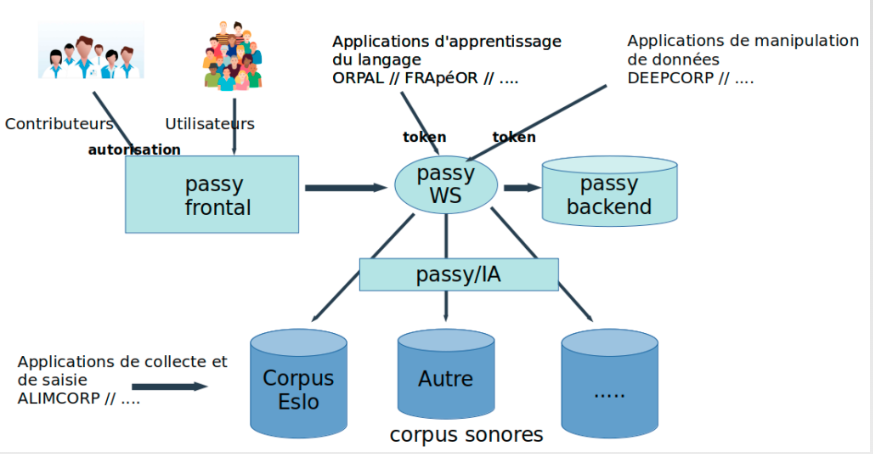
Création d’un Workflow :

Elaboration d’un workflow de traitements pour permettre à la plateforme d’avoir un côté communautaire, on envisage dès le départ une saisie multiple par des utilisateurs de type contributeur. Ce qui permettra d’avoir, vu le chantier, des forces vives pour alimenter et corriger les entrées. Dans ce circuit d’alimentation deux voies sont prévues : une alimentation manuelle et une alimentation automatique.
Alimentation manuelle : réservée aux contributeurs, elle permettra à des utilisateurs spécifiques de proposer des corrections et ajouts des données à partir d’une interface dédiée. Un environnement
Alimentation automatique : déclenchée par le Backend de la plateforme pour l’extraction de corpus sonores. cet agent IA devra en permanence sonder des corpus existants et des fonds sonores publics pour en extraire des séquences et les proposer à la plateforme.
Pour ces deux circuits d’alimentation nous mettons en place un Workflow qui aura pour objectif de valider les propositions des contributeurs et de la partie IA afin de garantir une grande qualité des données mises à la disposition des utilisateurs.
Extraction des données ESLO2 :
Constitution et extraction des entrées fournies par ESLO2 : le corpus nous permet d’extraire à partir des transcriptions C des enregistrements des illustrations sonores très variées des mots et de leur prononciation.
Création d’un script python pour extraire des fichiers de transcriptions les différentes informations.
Préparation de l’environnement pour les extractions: Installation des packages suivants pour faciliter et interpréter les données extraites dans un environnement python3.12
pip3 install spacy nlp nltk
python -m spacy download fr_core_news.sm
pip install git+https://github.com/ClaudeCoulombe/FrenchLeffLemmatizer.gitCes différents package vont nous permettre d’obtenir directement la lemmatisation des mots pour constituer un lexique et la morpho-syntaxe des expressions extraites le tout enregistrer dans deux collections de notre base de données MongoDB : eslo2 et lexique_eslo2
Retour expérience du parser XML : import xml.etree.ElementTree as ET
1 / Ce package entre les versions 3.9 et 3.12 de python a évolué et l’emploi de getChildren pour trouver les enfants d’une branche de la structure XML n’est plus accessible dans les dernières versions.
2 / Interprétation des blocs à l’aide du parser.
Bloc classique :
<Turn speaker="spk1" startTime="403.994" endTime="407.699">
<Sync time="403.994"/>
oui mais je me suis excusé c'est bon là
<Sync time="406.048"/>
j'ai pas fait exprès
</Turn>
Bloc spécifique :
<Turn startTime="0" endTime="120.852" speaker="spk1">
<Sync time="0"/>
<Sync time="0.586"/>
<Event desc="rire" type="noise" extent="instantaneous"/>
<Sync time="1.409"/>
c'est moi
<Sync time="2.462"/>
<Sync time="120.295"/>
ça va ?
</Turn>
Attention aux lignes vides, lors de la recomposition du bloc, elles ne sont pas interprétées par le parser. Si on reconstitue ce bloc de la manière suivante ….<Sync time=”0″/><Sync time=”0.586″/><Event desc=”rire” type=”noise” extent=”instantaneous”/>…
le parser ne distingue pas les éléments intermédiaires et repositionne mal les groupes de mots. D’où l’ajout systématique d’une chaîne de caractères que l’on pourra distinguer et filtrer par la suite ….<Sync time=”0″/>YS<Sync time=”0.586″/>YS
Résultats de l’extraction à partir de 511 fichiers TRS des enregistrements d’ESLO2 :
62802 Blocs multi-speakers non interprétés
338951 Documents générés dans MongoDB pour les groupes de souffle
40753 entrées différentes ajoutées dans la lexique Eslo2.
Extraction des données ESLO 1 :
Résultats de l’extraction à partir de 346 fichiers TRS des enregistrements d’ESLO1 :
39265 Blocs multi-speakers non interprétés
400633 Documents générés dans MongoDB pour les groupes de souffle
38855 entrées différentes ajoutées dans la lexique Eslo1.
Restrictions:
Nous faisons le choix dans le traitement des transcriptions de ne pas prendre en compte les blocs multi-speakers pour éviter de la confusion et afin d’avoir des enregistrements clairs et précis.
Exemple de bloc multi-speakers
<Turn speaker="spk5 spk1" startTime="407.699" endTime="410.971">
<Sync time="407.699"/>
<Who nb="1"/>
bon tu es tu es
<Event desc="pi" type="pronounce" extent="instantaneous"/>
parce que c'est
<Event desc="rire" type="noise" extent="instantaneous"/>
<Who nb="2"/>
<Event desc="rire" type="noise" extent="instantaneous"/>
<Sync time="410.086"/>
<Who nb="1"/>
<Who nb="2"/>
</Turn>On peut constater que dans ce découpage les éléments ne sont pas assez précis et n’apportent pas d’informations supplémentaires pour notre plateforme passy, qui met en avant l’écoute et la prononciation des mots par un seul locuteur.
Détail du code pour l’extraction
def traite_bloc(bb,speakers,fichier):
"""
Traitement du bloc Turn pour en extraire les éléments
"""
global nb_speakers_multiple, liste_mots
tree = ET.ElementTree(ET.fromstring(bb))
root=tree.getroot()
Turn=root.attrib
# on regarde si plusieurs speakers
if "speaker" not in Turn:
print("pas de speaker dans le bloc")
return
tab_speakers=Turn["speaker"].split(" ")
D_bloc_recompose={}
if len(tab_speakers)<2 :
txt_complet=""
textes=[]
debut=Turn["startTime"]
ref_end=Turn["endTime"]
#on parcourt les deux listes en même temps
for indice,txt in zip(list(root), root.itertext()):
if "time" in indice.attrib : #<Sync time="407.699"/>
ref_debut= indice.attrib['time']
if debut!=ref_debut:
textes.append({"debut":debut, "fin":ref_debut,"texte":txt_complet.strip()})
debut=ref_debut
txt_complet=txt
#pour le dernier
textes.append({"debut":debut, "fin":ref_end,"texte":txt_complet.strip()})
for texte in textes:
D_bloc_recompose={}
if texte["texte"]!="" and texte["texte"]!="YS" :
mot_propre=texte["texte"].replace("'"," ").replace("?"," ")
tab_res = re.split('\s+', mot_propre)
for mot in tab_res:
if mot in liste_mots:
liste_mots[mot]+=1
else:
liste_mots[mot]=1
D_bloc_recompose["enreg"]=fichier
D_bloc_recompose["locuteur"]=speakers[Turn["speaker"]]["name"]
D_bloc_recompose["texte"]=texte["texte"]
D_bloc_recompose["morpho"]=[{y:x} for x,y in return_POS(texte["texte"])]
D_bloc_recompose["debut"]=texte["debut"]
D_bloc_recompose["fin"]=texte["fin"]
# on enregistre la structure directement dans MongoDB
mycol.insert_one(D_bloc_recompose)
else :
nb_speakers_multiple+=1
Modifications et adaptations suite réunion du 16/12/2025
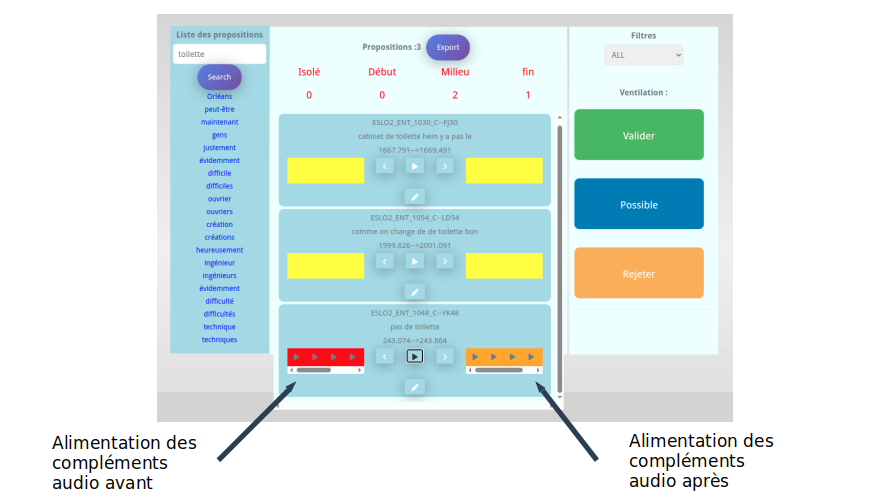
Pour ajouter la possibilité d’écouter les éléments sonores avant et après un segment il est nécessaire de disposer de la totalité des segments pour tous les enregistrements ENTRETIEN d’ESLO. Ensuite de réadapter le web service au niveau de Spring Boot pour permettre cette récupération. Pour ce faire on a implémenté de nouvelles entrées dans l’API get_avant_ et get_apres qui s’appuient sur le type de requête ci-dessous :
db.getCollection(‘eslo2’).aggregate([{“$addFields”:{nouv:{$toDouble:”$debut”}}},{$match:{$and:[{$expr:{$gt:[“$nouv”,280.261]}},{$expr:{$lt:[“$nouv”,301.261]}},{“enreg”:”ESLO2_ENT_1010_C”}]}}])
On génère un nouveau champ nouv pour transformer la donnée texte en donnée numérique afin de pouvoir la comparer.
// chercher les segments avant et après celui courant
// on va prendre le debut -10 et la fin + 10
@RequestMapping(value = "/get_avant_", method = POST)
@PostMapping("json")
public List<Proposition_IA> get_avant_(@RequestBody Map<String, String> body) {
String locuteur = body.get("locuteur");
double debut= Double.parseDouble(body.get("debut"));
double fin= Double.parseDouble(body.get("fin"));
String enreg= body.get("enreg");
AddFieldsOperation Addfield = Aggregation.addFields().addField("nouv").withValue(ConvertOperators.ToDouble.toDouble("$debut")).build();
// avant
Criteria critres = new Criteria().andOperator(
Criteria.where("nouv").lt(debut),
Criteria.where("nouv").gt(debut-10),
Criteria.where("enreg").regex(enreg));
MatchOperation matchStage = Aggregation.match(critres);
Aggregation aggregation = Aggregation.newAggregation(Addfield, matchStage);
AggregationResults<Proposition_IA> output_avant = mongoTemplate.aggregate(aggregation, "eslo2", Proposition_IA.class);
List<Proposition_IA> avant_result = output_avant.getMappedResults();
return avant_result;
} Description de la classe : propositions_IA
private String _id;
private String locuteur;
private String enreg ;
private String texte ;
private ArrayList<String> morpho ;
private double debut ;
private double fin ;
private Statut statut ;La partie Morpho a été neutralisée dans le visuel pour le moment. L’ensemble des résultats sont ensuite descendus au niveau du navigateur dans l’interface WEB et positionnés dans une div autour du bouton lecture. Ce qui permet à l’utilisateur de charger uniquement les éléments nécessaires à la compréhension du segment lors de l’analyse.
Implémentation de la prise de note :
Implémentation de la prise de note au niveau des entrées : on souhaite également conserver les informations associées au segment, pour ce faire on a aménagé un système de prise de note qui permet d’accompagner les chercheurs dans leur exploration et lors de leur sélection et ensuite de les partager entre eux. L’accès en modification est autorisé au seul propriétaire de la note. Au niveau du web service il a fallu mettre en place un système de gestion de ces notes dans deux contextes: contexte lors du travail préparatoire BROUILLON et lors de la sélection des entrées VALID, ce qui correspond à l’onglet Corpus ESLO2 et Exemplaires de l’interface.
Une collection Annotation dédiée a été générée pour conserver ce type d’information et est reliée par l’ID à l’entrée correspondante.
Interface avec Praat/Elan
La plateforme PASSY doit permettre aux utilisateurs de travailler dans les meilleures conditions et d’offrir les fonctionnalités nécessaires pour les différentes phases. On a identifié plusieurs phases :
- phase d’alimentation qui se concentre principalement au niveau du module de supervision et qui est dédiée aux expert(e)s ,
- phase d’exploitation/extraction qui est dédiée à toue les utilisateurs de la plateforme
Pour ces deux phases il semble intéressant d’offrir des outils d’analyse de signaux sonores sur un ou plusieurs éléments afin d’avoir des mécanismes de comparaison et d’extraction qui reposent sur des métriques associés directement au signal que l’on pourra croiser avec les méta-données.
Interfaçage avec Praat :
Praat est disponible en version desktop sur les environnements Windows, Linux et Mac. Il offre également des possibilités de scripts qui permettent d’encapsuler des traitements en lots sur des sources définies. De plus une des versions de Praat est disponible en mode commande. Exemples de scripts https://github.com/FieldDB/Praat-Scripts
Donc le dispositif que l’on envisage avec ce type de solution est le suivant :
- Définir les fonctionnalités que l’on souhaite offrir lors des différentes phases
- Phase de supervision — pour les expert(e)s
- Phase d’exploitation — pour les utilisateurs
- Traduire ces fonctionnalités en scripts
- Tester les scripts pour la production de résultats sur un ou plusieurs éléments sonores
- Tester l’intégration et l’exécution de ces scripts dans un environnement en mode commandes (sans interface graphique )
- Intégrer dans un web service le dispositif d’appel et de restitution des résultats de traitements à la plateforme Passy
Implémentation et évaluation sous Python
Sous python : voir le site de https://parselmouth.readthedocs.io/en/stable/
Installation sous linux : pip install praat-parselmouth
Exemple de mise en oeuvre avec une extraction simple
import parselmouth
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Matplotlib is building the font cache; this may take a moment.
sns.set() # Use seaborn's default style to make attractive graphs
plt.rcParams['figure.dpi'] = 100 # Show nicely large images in this notebook
snd = parselmouth.Sound("audio/the_north_wind_and_the_sun.wav")
plt.figure()
plt.plot(snd.xs(), snd.values.T)
plt.xlim([snd.xmin, snd.xmax])
plt.xlabel("time [s]")
plt.ylabel("amplitude")
plt.show() # or plt.savefig("sound.png"), or plt.savefig("sound.pdf")Pour extraire une partie du signal et faire une représentation plus fine d’une
Utilisation de cette solution sous forme de web service via flask voir
Détail de la bibliothèque : parselmouth
| parselmouth.AmplitudeScaling( ) | parselmouth.PitchUnit() | parselmouth.SoundFileFormat() |
| parselmouth.CC( ) | parselmouth.praat () | parselmouth.SpectralAnalysisWindowShape() |
| parselmouth.Data() | parselmouth.PraatError() | parselmouth.Spectrogram() |
| parselmouth.Formant() | parselmouth.PraatFatal() | parselmouth.Spectrum() |
| parselmouth.FormantUnit( | parselmouth.PRAAT_VERSION | parselmouth.TextGrid() |
| parselmouth.Function( ) | parselmouth.PRAAT_VERSION_DATE | parselmouth.Thing( |
| parselmouth.Intensity( ) | parselmouth.read( ) | parselmouth.TimeFunction( |
| parselmouth.Interpolation() | parselmouth.Sampled( ) | parselmouth.ValueInterpolation() |
| parselmouth.Matrix() | parselmouth.SampledXY() | parselmouth.Vector() |
| parselmouth.MFCC( ) | parselmouth.SignalOutsideTimeDomain | parselmouth.VERSION |
| parselmouth.Pitch() | parselmouth.Sound( ) | parselmouth.WindowShape() |
Fonctions associées à parselmouth.Sound()
Code exemple pour le web service et intégration dans notre contexte
%%writefile server.py
from flask import Flask, request, jsonify
import tempfile
app = Flask(__name__)
@app.route('/pitch_track', methods=['POST'])
def pitch_track():
import parselmouth
# Save the file that was sent, and read it into a parselmouth.Sound
with tempfile.NamedTemporaryFile() as tmp:
tmp.write(request.files['audio'].read())
sound = parselmouth.Sound(tmp.name)
# Calculate the pitch track with Parselmouth
pitch_track = sound.to_pitch().selected_array['frequency']
# Convert the NumPy array into a list, then encode as JSON to send back
return jsonify(list(pitch_track))