
POC : InfluxDB
Objectifs du POC : mettre en place la solution initiale du site SNO avec sa base de données Postgresql et une solution avec la base de données InfluxDB. Pouvoir définir un jeu de requêtes et de traitements pour les deux solutions. Les aspects de performances et de consommation de ressources seront prises en compte ainsi que les aspects de maintenance et d’évolution de l’ensemble.
Solution de stockage de séries temporelles provenant principalement de matériels. Les concepts liés à cette solution sont :
- database
- field Key
- field Set
- filed Value
- measurement
- point
- retention policy
- series
- tag Key
- tag Set
- tag Value
- timestamp : quand la mesure a été effectuée, précision en nanosecondes
Mise en oeuvre du POC : à partir des données extraites d’ICOS sur la tourbière de la Guette pour allons mettre en place une solution pour effectuer des benchs entre les deux solutions native Postgresql avec sa vue matérialisée et InfluxDB.
Fichier de lancement de la partie serveur
docker run --rm -p 8181:8181 \
-v $PWD/data:/var/lib/influxdb3/data \
-v $PWD/plugins:/var/lib/influxdb3/plugins \
-e DOCKER_INFLUXDB_INIT_ADMIN_TOKEN_FILE=./.env.influxdb2-admin-token \
influxdb:3-core influxdb3 serve \
--node-id=my-node-0 \
--object-store=file \
--data-dir=/var/lib/influxdb3/data \
--plugin-dir=/var/lib/influxdb3/plugins
Lancement de la partie visualisation :
docker run --detach \
--name influxdb3-explorer \
--publish 8988:80 \
--publish 8989:8888 \
influxdata/influxdb3-ui \
--mode=admin
Pour démarrer les deux conteneurs, il faut créer au préalable un compte utilisateur influxdb sur le serveur lui affecter les PID/GID à 1500 et lui affecter les deux répertoires data et plugins.
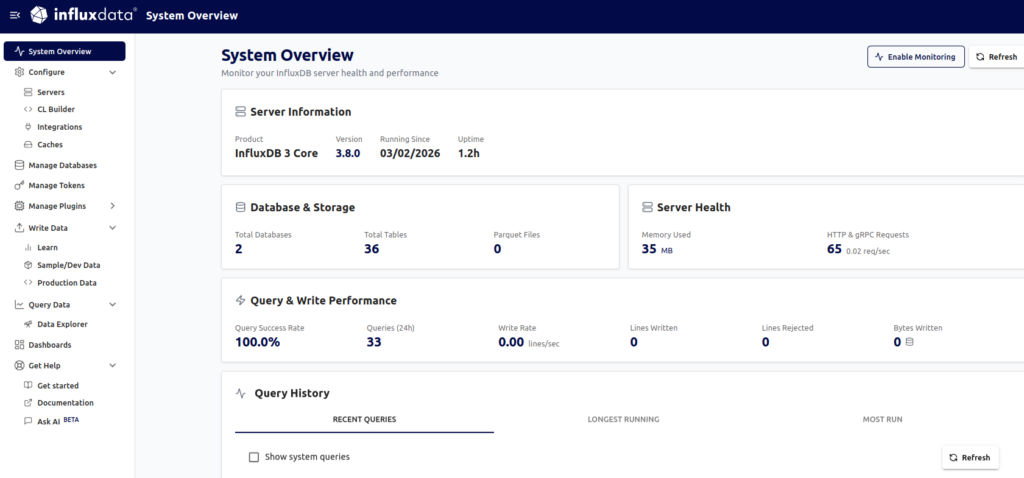
Démarrage de la partie visualisation et ajout du premier noeud http://localhost:8988/system-overview
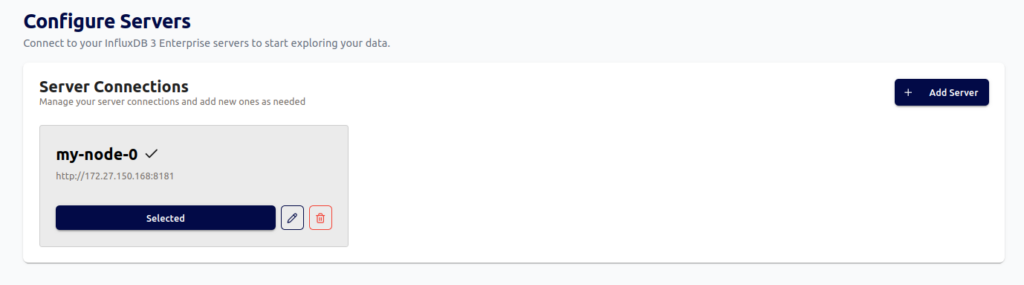
Dans la partie configure il faut ajouter le premier noeud de votre infrastructure pour cela il va falloir fournir également un token. Pour obtenir le token, connecter sur l’instance du noeud et exécuter la commande suivante: influxdb3 create token –admin
Cette commande retourne le token qu”il faut sauvegarder et renseigner lors de la création d’un node.
Trois éléments à fournir : nom, l’URL et le token. Pour l’URL indiquer l’adresse IP de la machine et pas localhost.
Accès via API à la base de données
REST API /api/v3/query_sqlAPI
Chargement des données issues de ICOS pour la tourbière de la Guette de 2017 à 2022
Plusieurs tentatives ont été réalisées en passant parle module import csv mais problème de lecture de la données TIMESTAMP_START et la convertir en time (valeur de référence pour la mesure).
Du coup, on se rabat sur un script python pour transformer les données et les importer dans la base.
Structure des données à importer : on a deux timestamp de start et de end de la mesure, la première valeur va servir de référence et sera remontée dans l’attribut time de l’enregistrement.
Code de chargement des données d’ICOS pour la Guette voir
Plusieurs petits problèmes au chargement des données dans le système dû à la valeur de TIMESTAMP et à l’insertion des éléments. Pour cela il est nécessaire de convertir les valeurs avant insertion.
# -----------------------------------------------------------------
# Y. Stroppa SPGoO/OSUC
# 04/02/2026
# Script développé pour permettre l'importation des données du SNO dans Influxdb
# -----------------------------------------------------------------
from influxdb_client import WritePrecision, InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
import pandas as pd
import time
from datetime import datetime
import csv
# paramètres de la connexion avec la serveur influxdb
url = 'http://192.168.150.168:8181'
token = 'TOKEN A RECUPERER SUR LE SERVEUR'
org = 'my-org'
bucket = 'my-sno'
# Chargement des données à partir du fichier externe CSV
f=open('ICOSETC_FR-LGt_METEO_L2.csv', newline='')
reader = csv.reader(f,delimiter=',', quotechar='|')
headers = next(reader, None)
def is_float(element:any)->bool:
if element is None:
return False
try:
float(element)
return True
except ValueError:
return False
client=InfluxDBClient(url=url, token=token, org=org)
write_api=client.write_api(write_options=SYNCHRONOUS)
for row in reader:
p = Point("sonde")
for h, v in zip(headers, row):
if h=="TIMESTAMP_START": # or h=="TIMESTAMP_END":
v+="00"
v=time.mktime(datetime.strptime(v,"%Y%m%d%H%M%S").timetuple())
print(type(v))
p.time(datetime.fromtimestamp(v),WritePrecision.MS)
elif h=="TIMESTAMP_END":
v=time.mktime(datetime.strptime(v,"%Y%m%d%H%M").timetuple())
p.field(h,v)
else:
p.tag("location", "La Guette")
value=v
if is_float(v):
value=float(v)
p.field(h,value)
# Ecriture de l'élément dans la base
write_api.write(bucket=bucket, record=p)