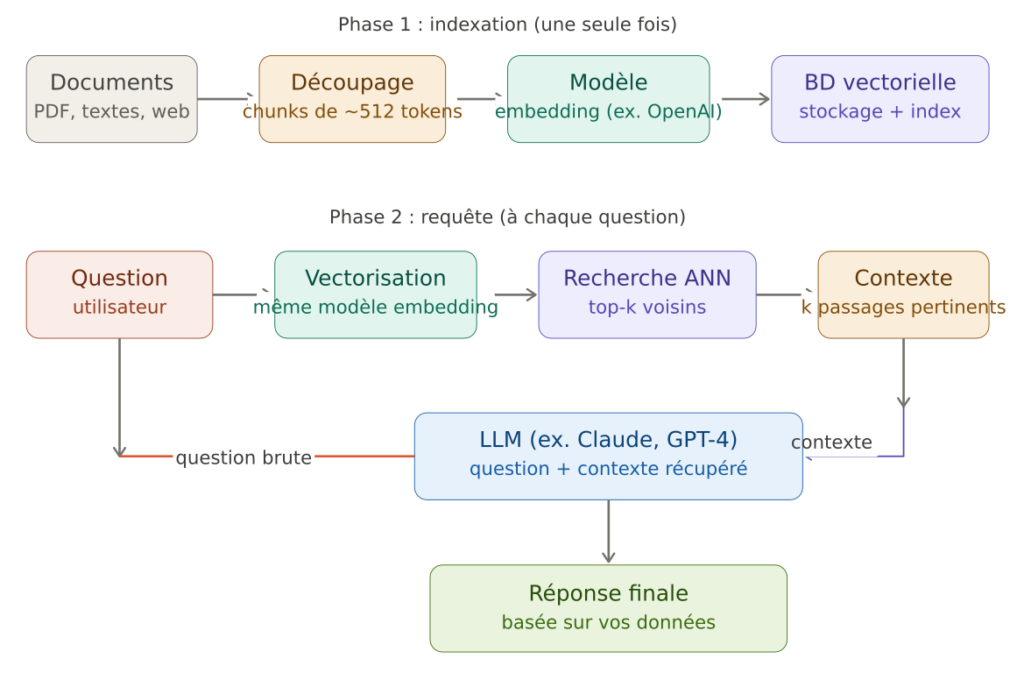
Première description d’une base de données vectorielles
Lorsqu’on va vouloir comparer les éléments qui ressemblent à d’autres, on n’ pas les outils nécessaires pour le faire dans une base de données classiques de type SQL ou NoSql. On dispose bien entendu de recherche exacte ou approximative qui se lient sur l’attribut : like ‘%…%’ ou avec des expressions régulières.
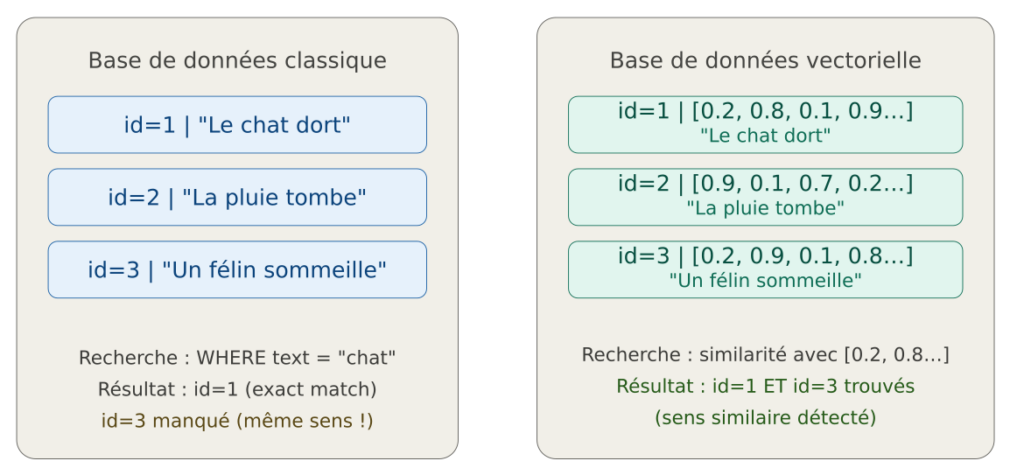
Qu’est ce qu’un vecteur (Embedding)
Un embedding est une représentation numérique d’une donnée (texte, image, son) sous forme de liste de réels. Ce vecteur encode le sens ou les caractéristiques de la donnée dans un espace mathématique.
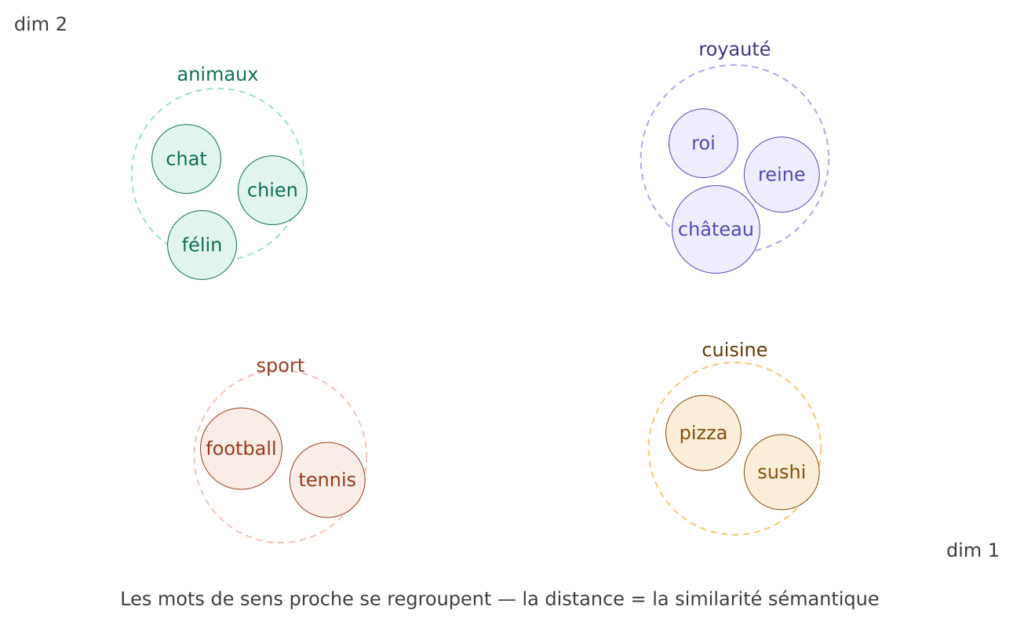
Les mots de sens proche se regroupent – la distance = la similarité sémantique. En réalisté, les embeddings ont des centaines ou milliers de dimensions (OpenAI text-embedding-3-small = 1536 dimensions).
Comment mesurer la similarité ?
La mesure la plus courante est la similarité cosinus – elle calcule l’angle entre deux vecteurs.
Le défi : recherche dans des millions de vecteurs
Comparer un vecteur à tous les vecteurs de la base (en force brute) une par une devient intenable à grande échelle. Les bases de données vectorielles utilisent des index spéciaux pour trouver rapidement les voisins les plus proches.
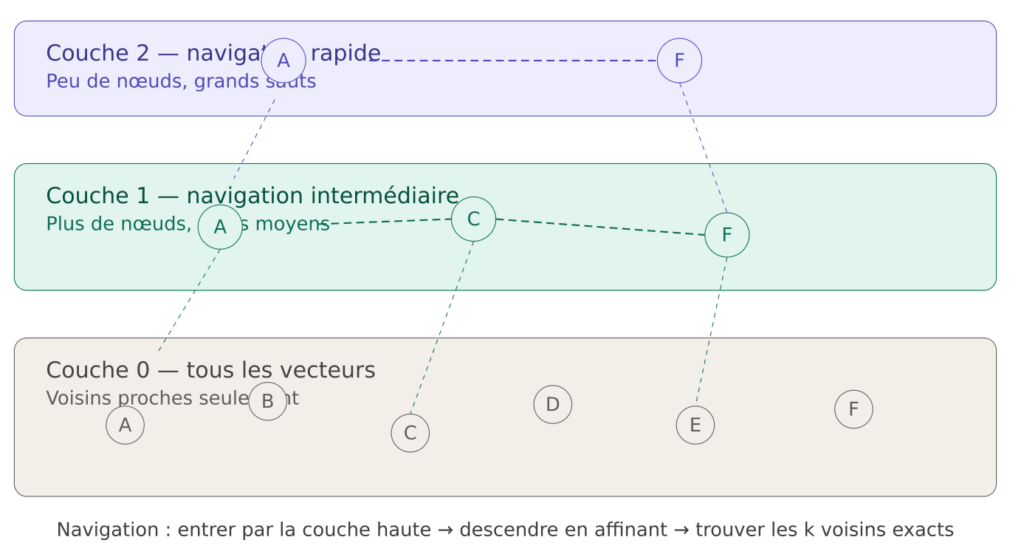
L’algorihme phare est HNSW ( Hierarchical Navigable Small World)
HNSW atteint des complexités sub-linéaires (~O(log(n)) contre O(n) pour la recherche brute. D’autres algorithmes existent IVF(Inverted File Index), PQ(Product Quantization, Scann, etc.
Architecture d’un pipeline RAG